
SNNAP (Systolic Neural Network Accelerator on Programmable logic) is an FPGA-based co-processor implemented on an ARM system-on-a-chip (SoC) that accelerates programs that can tolerate imprecision. To leverage SNNAP, programs have to undergo a process called neural transformation. Neural transformation takes a computationally demanding region of code in a program, and approximates it with a neural network. This neural network can then be efficiently evaluated on a specialized neural accelerator, SNNAP. This two-phase process of approximation and acceleration can bring substantial speedups and energy savings to many applications, especially to applicaiton that deal with inherently noisy data.
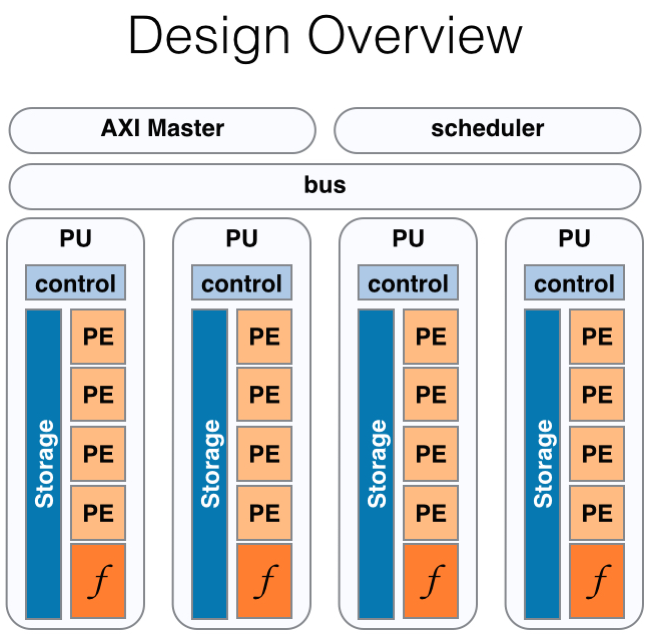
SNNAP is implemented on the programmable fabric of the Zynq, a commercial ARM-based SoC that incorporates an FPGA on the same die. This tight integration between the processors and the programmable fabric offers interesting opportunities for fine-grained acceleration, which is often required in the context of neural acceleration. SNNAP offloads computation by performing low-latency coherent memory accesses directly to the CPU’s caches. Additionally, SNNAP is design to exploit a parallelism in programs: it is composed of multiple processing units that can evaluate neural networks in parallel. Each processing unit utilizes DSP slices arranged in a systolic array to evaluate neural networks efficiently. SNNAP gets its flexibility from a micro-coded sequencer, and reconfigurable weight banks. This means that neural network ‘frames’ can be loaded into a processing unit dynamically.
SNNAP was evaluated on a set of diverse benchmarks that span over application domains such as image processing, machine learning, image compression etc. and provides a 3.8x speedup on average, and 2.8x energy savings on average.
This is a joint project at University of Washington and Georgia Tech.
Contacts: Thierry Moreau and Luis Ceze
Collaborators
Thierry Moreau, Mark Wyse, Jacob Nelson, Adrian Sampson, Hadi Esmaeilzadeh, Luis Ceze and Mark Oskin.
Publications
SNNAP: Approximate Computing on Programmable SoCs via Neural Acceleration. Thierry Moreau, Mark Wyse, Jacob Nelson, Adrian Sampson, Hadi Esmaeilzadeh, Luis Ceze, Mark Oskin. HPCA 2015.
Source release
The SNNAP hardware design and the compiler framework to support neural acceleration is accessible now upon request. Please email Thierry Moreau directly to obtain access to the source. If you wish to receive updates, please submit your email address below (or using this form).